时间:2021-05-06 点击:1500次
为了解决自动语音识别在特定设备上个性化的问题,来自苹果的二十余位研究者创建了一个能够进行联邦评估和优化的系统。
与服务器端处理(server-based processing)相比,终端用户设备上的处理(也可称设备上处理)是促进终端用户隐私的一种重要方法。这种策略可以扩展至很多机器学习(ML)解决方案,如预测键盘或设备上听写(dictation)。此外,为了获得良好的用户体验,这些 ML 系统的个性化往往至关重要。比如,实现用户词汇与语言结构的个性化在上述两种系统的使用场景下非常重要。
基于这些现状,来自苹果公司的二十余位研究者着手解决关于自动语音识别(automatic speech recognition, ASR)的特定设备上个性化用例。这种用例需要对一种个性化算法的全局参数(即所有终端用户共有)进行评估与调整,其中涉及的这种个性化算法通过获取仅设备上可用的数据来创建特定于设备的 ASR 语言模型。这种初始用例最终创建了一个能够评估和调整跨终端用户设备上 ML 系统的通用系统,也就是这种系统可以进行联邦评估和优化(federated evaluation and tuning, FE&T)。研究者通过抽象(abstract away)任何特定用例特定 bits 实现了该系统的泛化,并集中于 FE&T 共有的需求,如联邦任务分布与执行、设备上评估数据存储区以及中央服务器上的任务结果吸收和处理对该系统进行了泛化。

联邦学习(FL)指的是跨终端用户设备对模型进行基于梯度的优化,联邦学习主要应用于神经模型。近年来,许多联邦学习出版物影响了研究者扩展系统以更好地支持联邦学习。该论文的内容主要集中在将系统应用于设备上的个性化。
下图 1 显示了该研究中的高级(high level)系统设计,整个系统设计支持任意联邦任务。使用私有联邦学习(private federated learning, PFL)附加功能需要联邦学习任务的执行插件,从而可以为联邦神经网络训练提供支持,配音怎么最终模型更新会经过统计噪声处理保证差分隐私(differential privacy, DP)。
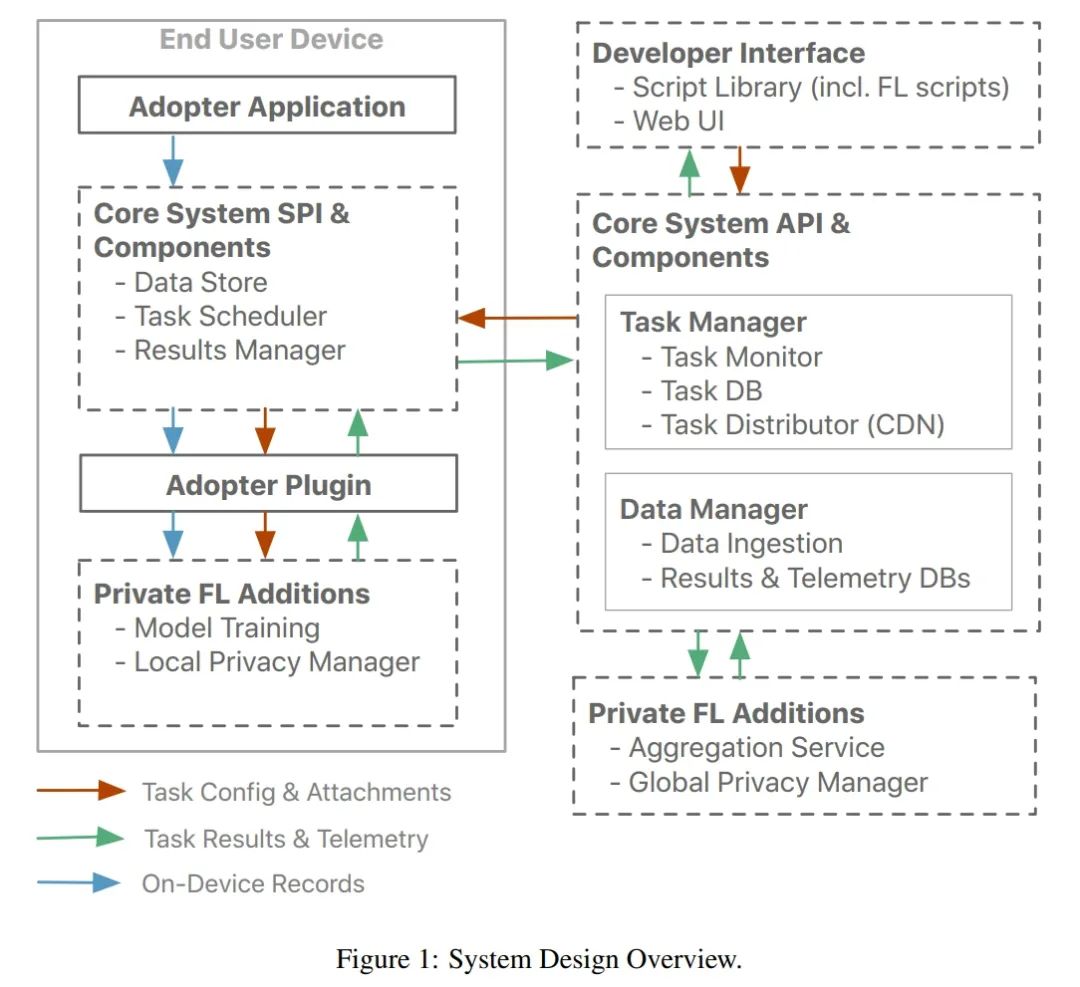
设备参与由系统级(system-level)前提条件和特定于联邦任务的前提条件共同控制。就前者而言,参与仅限于正版设备,并通过类似于 SysBon 的设备认证机制来保证。另外,设备需要被选到数据收集程序,从而使终端用户可以选择退出参与。该研究限制选中设备的参与,这一设计选择具有引入偏置的潜力。
设备上的数据处理。该系统提供设备上的数据存储区,建议将应用程序用于记录用户交互数据和相关实际情况。退出数据收集程序时,将自动清除存储数据,如果退出该设备,则写入请求将被拒绝。此外,数据存储提供了用于常见设备上数据保留策略,每个应用程序都可以配置的默认实现。
结果数据处理。尽管存储在该设备上数据存储区中的数据不会离开设备,但是从该数据中得出的任务结果(即评估指标(FE&T)和统计上受干扰的模型更新(FL))将通过加密通道发送到服务器。该研究还共享在设备上数据存储区中存储的特定于应用程序的全部数据记录信息,作为系统健康状况遥测数据的一部分,以帮助评估可用于特定于应用程序的联邦任务执行的设备总数。在服务器端记录数据(结果和遥测)时,配音怎么该研究会剥离所有用户和设备标识(例如 IP 地址),以避免此类服务器记录的数据能够绑定回特定用户或设备。终端用户可以在设备上的隐私设置中检查与服务器共享的数据。
设备上的组件包括数据存储区,任务计划器和结果管理器。结果管理器主要负责发回任务结果并填充设备上的 DB,该 DB 允许终端用户检查与服务器共享的数据。除了任务结果,结果管理器还收集与健康相关的遥测数据并将其发送到服务器系统。
服务器组件包括任务管理器,数据管理器和开发者接口。任务管理器是服务器的核心组件。它管理所有任务及其到 CDN 的附件(例如模型)的存储和发布,以及退役任务。一旦任务在预定义的时间段内处于活动状态,或者一旦收到目标数量的结果,任务就会退役。任务退役后到达服务器端的任何混乱结果都将被忽略。任务管理器还监视传入结果的流,以确保产生过多流量的任务不会淹没基础架构。最后,该组件还确保定期并自动从中央结果数据库中清除旧任务的结果。
近年来,许多联邦学习发表研究启发我们使用联邦平均 [1] 将系统扩展到更好地支持联邦学习。对于联邦学习应用程序,设备上任务执行和服务器端结果处理(在较高级别上)是相同的。因此,研究者添加了共同的组件,可以为两者提供有效的实现。对于设备上的任务执行,神经网络训练库提供了模型训练支持。服务器端结果处理由中央聚合服务提供,该服务将单个模型更新组合在一起以计算当前训练迭代的平均模型。借助联邦学习训练脚本,系统中的中央数据库中会有预定义数量的单个模型更新,聚合会自动开始。联邦学习训练脚本负责在多个训练迭代之间协调整个模型训练。
研究者介绍了两种以 ML 系统个性化为中心的联邦优化(federated tuning, FT)应用,以突出 FT 对于设备上个性化的适用性。首个应用是新闻个性化。由于设备上 ground truth 生成在新闻个性化语境中面临的挑战更少,所以研究者将重心放在了采取的特定 FT 方法上。第二个应用是 ASR 个性化,这是研究者的初始用例。
对于新闻个性化,设备上评估或数据优化,包括 ground truth 的概念,这些都可以从用户与新闻内容的交互中获得。举例而言,人们可以在设备上存储用户已阅读或者已看到但并未阅读文章的信息。这一用例的设备上系统插件接受不同数值的参数。
运行单个 FT 任务迭代会出现数百万个损失以及来自数千个设备的配置对。每个迭代的结果通过特定于应用的协调器脚本在服务器端进行平滑处理,以确定下次迭代的搜索空间。n 个参数的优化可以作为具有 k 大小聚类的 n 维聚类问题实现,其中 k 可以进行优化。具有最小预测的聚类通过以下公式得到确定:
为了提升这种方法的有效性,研究者展示了两种不同 FT 运行的结果。FT 运行的不同体现在两方面,分别是正被优化的个性化算法参数的数量以及 ground truth 如何在设备上以基于规则的方式得到(如文章标题是否被选中)。下表 1 展示了这些细节,包括预测损失相对减少时的结果。配音怎么

对于这两种 FT 运行,研究者都进行了实时 A/B 实验,以度量优化后个性化算法参数对终端用户体验的影响,结果如下表 2 所示。
研究者介绍了跨终端用户设备和服务器分布的「混合」ASR 系统解决方案。该 ASR 系统使用服务器端的 ASR 系统融合来计算自身的最终识别结果,其中高度个性化设备上 ASR 系统的识别结果与通用性更强的服务器端 ASR 系统的结果相结合。本研究提出的转录用户语音输入的 ASR 引擎使用了一个包含数十万个单词的通用词汇表。
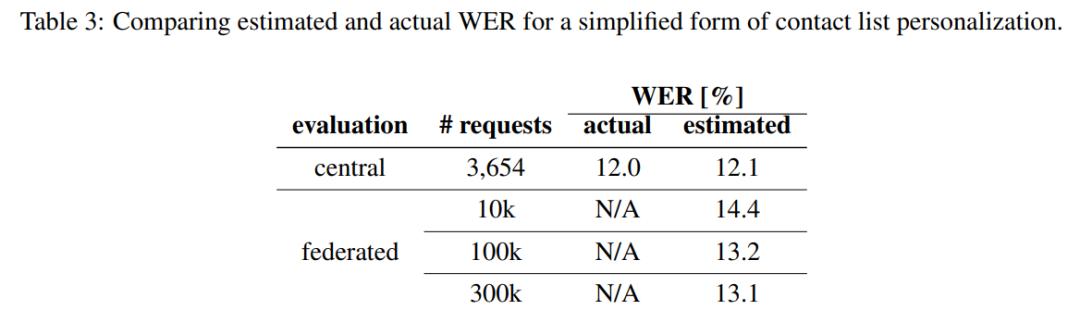
下表 3 展示了该研究 eWER 指标与实际 WER 度量的对比情况。对比结果在单一数据源的简化个性化语境中,即没有对用户通讯簿中的联系人姓名进行频率计数(frequency count)。
下表 4 展示的结果涉及 3,851 个 assistant directed 请求,其中最终自动转录结果因为 ASR 系统融合出现了变化。
